问题描述

Whiskas 猫粮由 Uncle Ben’s 生产。 本叔叔希望尽可能便宜地生产他们的猫粮产品,同时确保它们符合规定的营养分析要求显示在罐头上。因此,他们希望改变每个的数量 使用的成分(主要成分是鸡肉、牛肉、羊肉、 大米、小麦和凝胶),同时仍符合其营养标准。
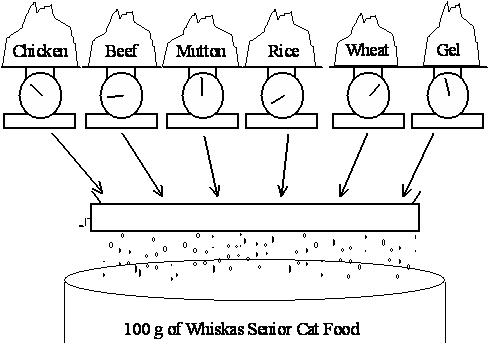
鸡肉、牛肉和羊肉的成本为 0.013 美元、0.008 美元和0.010 美元,而大米、小麦和凝胶的成本为 分别为 0.002 美元、0.005 美元和 0.001 美元。(所有费用均为每克,忽略维生素和矿物质成分,这些成本可能非常小)
每种成分都有助于蛋白质、脂肪、 最终产品中的纤维和盐。每份贡献(以克为单位) 下表给出了成分的克数。
东西 蛋白 脂肪 纤维 盐 鸡 0.100 0.080 0.001 0.002 牛肉 0.200 0.100 0.005 0.005 羊肉 0.150 0.110 0.003 0.007 米 0.000 0.010 0.100 0.002 麦麸 0.040 0.010 0.150 0.008 凝胶 0.000 0.000 0.000 0.000
简化配方
首先,我们将考虑一个简化的问题来构建一个简单的 Python 模型。
识别决策变量
假设 Whiskas 只想用两种成分制作他们的猫粮: 鸡肉和牛肉。我们将首先定义我们的决策变量:
x 1 = 猫粮中鸡肉的占比 x 2 = 猫粮中牛肉的占比 \begin{split}x_1 &= \text{ 猫粮中鸡肉的占比}\\ x_2 &= \text{ 猫粮中牛肉的占比}\end{split} x1x2= 猫粮中鸡肉的占比= 猫粮中牛肉的占比
必须注意这些变量的限制(大于零),但 对于 Python 实现,它们不会单独输入或列出,也不会与其他约束一起输入或列出。
制定目标函数
要求成本最低
目标函数为: min 0.013 x 1 + 0.008 x 2 \textbf{ min } 0.013 x_1 + 0.008 x_2 min 0.013x1+0.008x2
制约因素
变量的约束条件是它们的总和必须为 100,并且满足营养需求:
1.000 x 1 + 1.000 x 2 = 100.0 0.100 x 1 + 0.200 x 2 ≥ 8.0 0.080 x 1 + 0.100 x 2 ≥ 6.0 0.001 x 1 + 0.005 x 2 ≤ 2.0 0.002 x 1 + 0.005 x 2 ≤ 0.4 \begin{split}1.000 x_1 + 1.000 x_2 &= 100.0\\ 0.100 x_1 + 0.200 x_2 &\ge 8.0\\ 0.080 x_1 + 0.100 x_2 &\ge 6.0\\ 0.001 x_1 + 0.005 x_2 &\le 2.0\\ 0.002 x_1 + 0.005 x_2 &\le 0.4\\\end{split} 1.000x1+1.000x20.100x1+0.200x20.080x1+0.100x20.001x1+0.005x20.002x1+0.005x2=100.0≥8.0≥6.0≤2.0≤0.4
简化问题的解决方案
为了获得这个线性规划的解,我们可以写一个简短的 在 Python 中编程来调用 PuLP 的建模函数,然后 调用求解器。这将逐步解释如何编写此 Python 程序。建议您自己重复练习。代码 对于此示例,可以在WhiskasModel1.py
导入pulp库
导入 PuLP 的函数以在代码中使用:
# Import PuLP modeler functions
from pulp import *
创建问题变量
使用该函数创建一个名为prob(虽然它的名字并不重要)的变量。它有两个参数,第一个参数是此问题的任意名称(作为字符串),第二个参数取决于您要解决的 LP 类型:LpMinimize(求最小值) 或 LpMaximize(求最大值)
# 创建'prob' 变量包含该问题数据
prob = LpProblem("The Whiskas Problem", LpMinimize)
创建决策变量
决策变量是使用类创建的。
example表示decision variable name,决策变量名,
lowBound和upBound:下界和上界, 默认分别是负无穷到正无穷,
参数 cat 用来设定变量类型,可选参数值:
‘Continuous’ 表示连续变量(默认值)、
‘Integer ’ 表示离散变量(用于整数规划问题)、
‘Binary ’ 表示0/1变量(用于0/1规划问题)
如果输入了前几个参数,其余的参数 被忽略(如图所示),它们采用其默认值。但是,如果您希望指定第三个参数,但您希望第二个参数是 默认值,您需要专门将第二个参数设置为默认值。即您不能将参数条目留空。 例如:
LpVariable("example", None, 100)
或:
LpVariable("example", upBound = 100)
要显式创建此问题所需的两个决策变量,请执行以下操作:
# 牛肉和鸡肉的两个变量的下限设为0
x1 = LpVariable("鸡肉占比", 0, None, LpInteger)
x2 = LpVariable("牛肉占比", 0)
目标函数
决策变量现在开始与问题变量一起收集问题数据。
首先通过prob+=输入目标函数,其中语句末尾的重要逗号和短字符串解释这个目标函数是什么:
# 这个目标函数先加到'prob'
prob += 0.013 * x1 + 0.008 * x2, "每个罐头的总花费"
约束条件
现在输入约束条件(注意:在定义变量时已经包含了任何“非负数”的约束条件)。再次使用 ‘+=’ 运算符完成,因为我们要向变量添加更多数据。在此之后逻辑上输入约束,并使用约束方程末尾的逗号和短字符串解释该约束的原因:
# 这五个约束条件已输入
prob += x1 + x2 == 100, "总克数"
prob += 0.100 * x1 + 0.200 * x2 >= 8.0, "蛋白质需求"
prob += 0.080 * x1 + 0.100 * x2 >= 6.0, "脂肪需求"
prob += 0.001 * x1 + 0.005 * x2 <= 2.0, "纤维需求"
prob += 0.002 * x1 + 0.005 * x2 <= 0.4, "盐需求"
写入
现在输入了所有问题数据,函数可用于将此信息复制到 .lp 文件中,并放入目录中。代码成功运行后,可以使用文本编辑器打开这个.lp文件。
# 问题数据被写入一个 .lp 文件文件
prob.writeLP("WhiskasModel.lp")
求解
使用 PuLP 选择的求解器求解 LP。输入 在这种情况下,后面的括号留空,但它们可以是用于指定要使用的求解器(例如):prob.solve(CPLEX())
# 这个问题是使用 PuLP 选择的求解器来解决的
prob.solve()
状态
我们请求解决方案的状态,可以是 “未解决”、“不可行”、“无界”、“未定义”或“最佳”。状态的值以整数形式返回,必须使用字典转换成对其重要文本的含义。由于是 dictionary(),因此其输入必须放在方括号中:
# 该解决方案的状态被打印到屏幕上
print("Status:", LpStatus[prob.status])
打印结果
现在可以打印变量及其解析的最优值到屏幕。
# 每个变量都打印出其解析出的最优值
for v in prob.variables():
print(v.name, "=", v.varValue)
循环遍历所有问题变量名称(在本例中为x1和x2 )。然后,它打印每个变量名称,后跟一个 等号,后跟其最佳值。 并且是对象的属性。
优化的目标函数值被打印到屏幕上, 使用 value 函数。这确保了数字以正确的格式打印:
# 优化的目标函数值被打印到屏幕上
print("Total Cost of Ingredients per can = ", value(prob.objective))
然后,运行此文件应生成输出以显示 鸡肉占33.33%,牛肉占66.67%,鸡肉占66.67%。 每罐原料的总成本为 96 美分。
状态 Optimal
x1 = 34.0
x2 = 66.0
总花费 = 0.97
最终代码
from pulp import *
#创建问题变量prob
prob = LpProblem("混合问题",LpMinimize)
#创建决策变量
x1=LpVariable('x1',0,100,LpInteger)
x2=LpVariable('x2',0,100,LpInteger)
#定义目标函数
prob+=0.013*x1+0.008*x2
#定义约束条件
prob += x1 + x2 == 100, "总克数"
prob += 0.100 * x1 + 0.200 * x2 >= 8.0, "蛋白质需求"
prob += 0.080 * x1 + 0.100 * x2 >= 6.0, "脂肪需求"
prob += 0.001 * x1 + 0.005 * x2 <= 2.0, "纤维需求"
prob += 0.002 * x1 + 0.005 * x2 <= 0.4, "盐需求"
#求解
prob.solve()
print("状态", LpStatus[prob.status])
# 每个变量都打印出其解析出的最优值
for v in prob.variables():
print(v.name, "=", v.varValue)
# 打印目标函数的最优值
print("总花费 = ", value(prob.objective))
全配方
现在我们将用所有变量。虽然它可以用 Python 实现,除了上面的方法之外,我们将研究一种更好的方法,这种方法不会过多地混合问题数据和公式表述。这将可以更轻松地为其他测试更改任何问题数据。我们将以同样的方式通过代数定义问题:
-
识别决策变量
对于 Whiskas 猫粮问题,决策变量是我们在罐头中包含的不同成分。 由于罐头是 100 克,因此这些百分比也代表了每种成分包含的克数。 我们必须正式定义我们的决策变量,确保说明我们正在使用的单位。
请注意,这些百分比必须介于 0 和 100 之间。x 1 = 一罐猫粮中鸡肉占比 x 2 = 一罐猫粮中牛肉占比 x 3 = 一罐猫粮中羊肉占比 x 4 = 一罐猫粮中米占比 x 5 = 一罐猫粮中小麦占比 x 6 = 一罐猫粮中凝胶占比 \begin{split}x_1 &= \text{一罐猫粮中鸡肉占比}\\ x_2 &= \text{一罐猫粮中牛肉占比}\\ x_3 &= \text{一罐猫粮中羊肉占比}\\ x_4 &= \text{一罐猫粮中米占比}\\ x_5 &= \text{一罐猫粮中小麦占比}\\ x_6 &= \text{一罐猫粮中凝胶占比}\end{split} x1x2x3x4x5x6=一罐猫粮中鸡肉占比=一罐猫粮中牛肉占比=一罐猫粮中羊肉占比=一罐猫粮中米占比=一罐猫粮中小麦占比=一罐猫粮中凝胶占比
-
制定目标函数
对于 Whiskas 猫粮问题,目标是将总成本降至最低,每罐猫粮的成分。 我们知道每种成分的每克成本。我们决定每个的百分比 罐头中的成分,所以我们必须除以 100 再乘以 G中的罐头。这将为我们提供每个的重量(以 g 为单位) 成分:min 0.013 x 1 + 0.008 x 2 + 0.010 x 3 + 0.002 x 4 + 0.005 x 5 + 0.001 x 6 \min 0.013 x_1 + 0.008 x_2 + 0.010 x_3 + 0.002 x_4 + 0.005 x_5 + 0.001 x_6 min0.013x1+0.008x2+0.010x3+0.002x4+0.005x5+0.001x6
-
制定约束条件 威士忌猫粮问题的制约因素是:
-
百分比的总和必须构成整个罐头 (= 100%)。
x 1 + x 2 + x 3 + x 4 + x 5 + x 6 = 100 x_1 + x_2 + x_3 + x_4 + x_5 +x _6 = 100 x1+x2+x3+x4+x5+x6=100
-
符合规定的营养分析要求。“整罐”的约束是:为了满足营养分析要求,我们需要具备 每 100 克至少含 8 克蛋白质,6 克脂肪,但不超过 2 克纤维 和 0.4 克盐。为了制定这些约束,我们利用每种成分的贡献表。这允许我们对来自成分的蛋白质、脂肪、纤维和盐的总贡献制定以下限制条件:
0.100 x 1 + 0.200 x 2 + 0.150 x 3 + 0.000 x 4 + 0.040 x 5 + 0.0 x 6 0 ≥ 8.0 0.080 x 1 + 0.100 x 2 + 0.110 x 3 + 0.010 x 4 + 0.010 x 5 0 + 0.0 x 6 ≥ 6.0 0.001 x 1 + 0.005 x 2 + 0.003 x 3 + 0.100 x 4 0 + 0.150 x 5 + 0.0 x 6 ≤ 2.0 0.002 x 1 + 0.005 x 2 + 0.007 x 3 0 + 0.002 x 4 + 0.008 x 5 + 0.0 x 6 ≤ 0.4 \begin{split}0.100 x_1 +0.200 x_2 +0.150 x_3 +0.000 x_4 +0.040 x_5 +0.0 x_6 0&\ge 8.0 \\ 0.080 x_1 +0.100 x_2 +0.110 x_3 +0.010 x_4 +0.010 x_5 0+0.0 x_6 &\ge 6.0 \\ 0.001 x_1 +0.005 x_2 +0.003 x_3 +0.100 x_4 0+0.150 x_5 +0.0 x_6 &\le 2.0 \\ 0.002 x_1 +0.005 x_2 +0.007 x_3 0+0.002 x_4 +0.008 x_5 +0.0 x_6 &\le 0.4\end{split} 0.100x1+0.200x2+0.150x3+0.000x4+0.040x5+0.0x600.080x1+0.100x2+0.110x3+0.010x4+0.010x50+0.0x60.001x1+0.005x2+0.003x3+0.100x40+0.150x5+0.0x60.002x1+0.005x2+0.007x30+0.002x4+0.008x5+0.0x6≥8.0≥6.0≤2.0≤0.4
-
完整问题的解决方案
为了得到这个线性规划的解,我们再次编写一个 Python 中的短程序来调用 PuLP 的建模函数,然后调用求解器。此示例的代码发现于WhiskasModel2.py
与上次一样,建议在文件开头评论其 目的,以及作者姓名和日期。PuLP 函数的导入也以相同的方式完成:
"""
The Full Whiskas Model Python Formulation for the PuLP Modeller
Authors: Antony Phillips, Dr Stuart Mitchell 2007
"""
# Import PuLP modeler functions
from pulp import *
字典
接下来,在定义变量或问题类型之前,关键问题数据被输入到字典中。这包括成分列表,随后是每种成分的成本,以及它对四种营养素的百分比。这些值清晰地列出,即使是对编程知识不多的人也可以轻松更改。成分是键,数字是数据。
# 创建成分列表
Ingredients = ["CHICKEN", "BEEF", "MUTTON", "RICE", "WHEAT", "GEL"]
# 包括每种成分成本的字典
costs = {
"CHICKEN": 0.013,
"BEEF": 0.008,
"MUTTON": 0.010,
"RICE": 0.002,
"WHEAT": 0.005,
"GEL": 0.001,
}
# 包括每种成分对四种营养素贡献的字典
# 包括每种成分对蛋白质贡献的字典
proteinPercent = {
"CHICKEN": 0.100,
"BEEF": 0.200,
"MUTTON": 0.150,
"RICE": 0.000,
"WHEAT": 0.040,
"GEL": 0.000,
}
# 包括每种成分对脂肪贡献的字典
fatPercent = {
"CHICKEN": 0.080,
"BEEF": 0.100,
"MUTTON": 0.110,
"RICE": 0.010,
"WHEAT": 0.010,
"GEL": 0.000,
}
# 包括每种成分对纤维贡献的字典
fibrePercent = {
"CHICKEN": 0.001,
"BEEF": 0.005,
"MUTTON": 0.003,
"RICE": 0.100,
"WHEAT": 0.150,
"GEL": 0.000,
}
# 包括每种成分对盐贡献的字典
saltPercent = {
"CHICKEN": 0.002,
"BEEF": 0.005,
"MUTTON": 0.007,
"RICE": 0.002,
"WHEAT": 0.008,
"GEL": 0.000,
}
创建问题变量
创建变量以包含公式,并且通常的参数被传递到prob。
# 创建'prob' 变量包含该问题数据
prob = LpProblem("The Whiskas Problem", LpMinimize)
创建一个名为ingredient_vars的字典,其中包含 LP 变量,这些变量的下界被定义为零。字典的键是成分名称,数据是与每种成分相关联的变量名称。(例如羊肉:Ingr_MUTTON)
# 创建了一个名为 'ingredient_vars' 的字典,用于包含引用的变量
ingredient_vars = LpVariable.dicts("Ingr", Ingredients, 0)
由于和现在是带有 参考键作为成分名称,可以简单地提取数据 具有如图所示的列表推导。该函数将添加 元素。因此,目标函数很简单 输入并分配了一个名称:costsingredient_vars
# The objective function is added to 'prob' first
prob += (
lpSum([costs[i] * ingredient_vars[i] for i in Ingredients]),
"Total Cost of Ingredients per can",
)
进一步的列表推导式用于定义其他 5 个约束,这些约束也是描述它们的给定名称。
# The five constraints are added to 'prob'
prob += lpSum([ingredient_vars[i] for i in Ingredients]) == 100, "PercentagesSum"
prob += (
lpSum([proteinPercent[i] * ingredient_vars[i] for i in Ingredients]) >= 8.0,
"ProteinRequirement",
)
prob += (
lpSum([fatPercent[i] * ingredient_vars[i] for i in Ingredients]) >= 6.0,
"FatRequirement",
)
prob += (
lpSum([fibrePercent[i] * ingredient_vars[i] for i in Ingredients]) <= 2.0,
"FibreRequirement",
)
prob += (
lpSum([saltPercent[i] * ingredient_vars[i] for i in Ingredients]) <= 0.4,
"SaltRequirement",
)
在此之后,行等遵循与 在简化的示例中。
最佳解决方案是 60% 牛肉和 40% 凝胶,从而实现目标 功能价值为每罐 52 美分。
最终代码
from pulp import *
#创建问题变量prob
prob = LpProblem("混合问题",LpMinimize)
#字典导入
# 创建成分列表
Ingredients = ["CHICKEN", "BEEF", "MUTTON", "RICE", "WHEAT", "GEL"]
# 包括每种成分成本的字典
costs = {
"CHICKEN": 0.013,
"BEEF": 0.008,
"MUTTON": 0.010,
"RICE": 0.002,
"WHEAT": 0.005,
"GEL": 0.001,
}
# 包括每种成分对四种营养素贡献的字典
# 包括每种成分对蛋白质贡献的字典
proteinPercent = {
"CHICKEN": 0.100,
"BEEF": 0.200,
"MUTTON": 0.150,
"RICE": 0.000,
"WHEAT": 0.040,
"GEL": 0.000,
}
# 包括每种成分对脂肪贡献的字典
fatPercent = {
"CHICKEN": 0.080,
"BEEF": 0.100,
"MUTTON": 0.110,
"RICE": 0.010,
"WHEAT": 0.010,
"GEL": 0.000,
}
# 包括每种成分对纤维贡献的字典
fibrePercent = {
"CHICKEN": 0.001,
"BEEF": 0.005,
"MUTTON": 0.003,
"RICE": 0.100,
"WHEAT": 0.150,
"GEL": 0.000,
}
# 包括每种成分对盐贡献的字典
saltPercent = {
"CHICKEN": 0.002,
"BEEF": 0.005,
"MUTTON": 0.007,
"RICE": 0.002,
"WHEAT": 0.008,
"GEL": 0.000,
}
# 创建了一个名为 'ingredient_vars' 的字典,用于包含引用的变量
ingredient_vars = LpVariable.dicts("Ingr", Ingredients, 0,100)
#定义目标函数
prob += (
lpSum([costs[i] * ingredient_vars[i] for i in Ingredients]),
"Total Cost of Ingredients per can",
)
#定义约束条件
# The five constraints are added to 'prob'
prob += lpSum([ingredient_vars[i] for i in Ingredients]) == 100, "PercentagesSum"
prob += (
lpSum([proteinPercent[i] * ingredient_vars[i] for i in Ingredients]) >= 8.0,
"ProteinRequirement",
)
prob += (
lpSum([fatPercent[i] * ingredient_vars[i] for i in Ingredients]) >= 6.0,
"FatRequirement",
)
prob += (
lpSum([fibrePercent[i] * ingredient_vars[i] for i in Ingredients]) <= 2.0,
"FibreRequirement",
)
prob += (
lpSum([saltPercent[i] * ingredient_vars[i] for i in Ingredients]) <= 0.4,
"SaltRequirement",
)
#求解
prob.solve()
#输出结果
for v in prob.variables():
print(v.name, "=", v.varValue)
print("Status:", LpStatus[prob.status])
print("Total Cost of Ingredients per can = ", value(prob.objective))